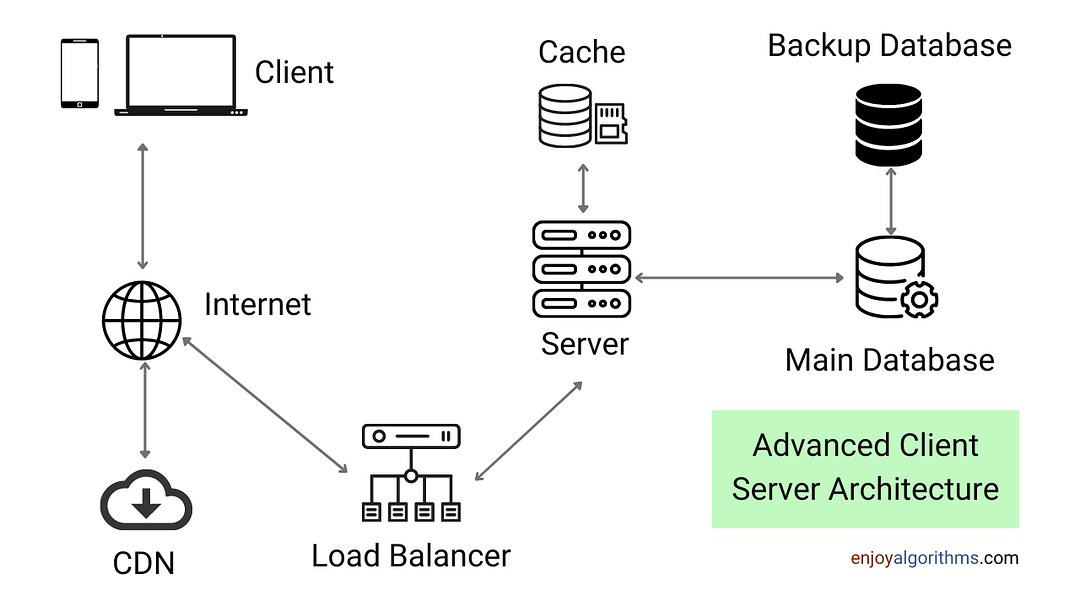
Every process or machine on a network can be either a server or a client in a client-server architecture. Powerful computers known as client servers are only used to manage network traffic, disk drives, and printers.
Client: Any machine that makes a request to the server is considered the client. When we visit a website, for instance, we request the webpage from its domain. A Client is either a person or an organization using as a service. In the IT context, the client is a computer/device, also called a Host, that actually uses the service or accepts the information. Client devices include laptops, workstations, IoT devices, and similar network-friendly devices.
Server: In contrast, the server is a computer that is intended to fulfill client requests. In the aforementioned example, the client requests the webpage, and the server provides it to the client in response. A Server in the IT world is a remote computer that provides access to data and services. Servers are usually physical devices such as rack servers, though the rise of cloud computing has brought virtual servers into the equation. The server handles processes like e-mail, application hosting, Internet connections, printing, and more.
Working of Client-Server Architecture
A client requesting data from any server first queries the DNS (Domain Name System) for the specific server's IP address. The IP Address is returned by the DNS server.
The client sends a request to that IP address, along with the port number configured for that specific application, and the server answers. The response packet is eaten by the application to which it belongs when the client gets the response message and determines the port number.
Types of Client-Server Architecture
Depending on the business logic used to process requests between the client and server, there are several forms of client-server architecture.
1-Tier Architecture
2-Tier Architecture
3-Tier Architecture
1-Tier Architecture
1 tier architecture also known as single-tier architecture, is referred to that kind of software architecture in which all the required components for the working of application are available under the same package.
It means that the user interface, business, layers are accessible by the application under the same local drive. Both the client and server reside in the same machine. It is the simplest application architecture used. But this tier is not suitable for a web application. As it can only access data available in a single computer or server.
MS Office is a prominent example of 1 tier architecture. This is a cost-efficient architecture and applications based on this are much easier to build. The major disadvantage of this architecture is that it cannot share information from one client machine to others. Sometimes the applications based on 1 tier are unable to work if some changes are done in the machine.
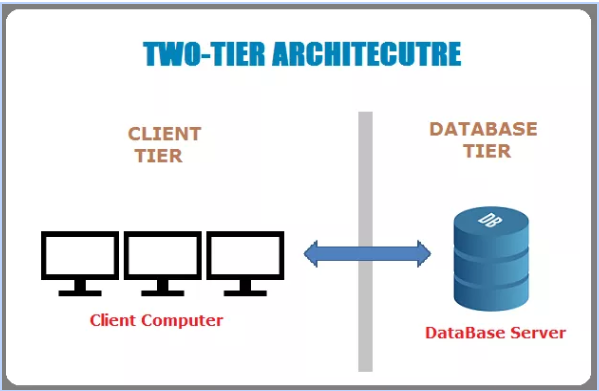
2-Tier Architecture
2 tier architecture is the one in which the user interface layer and the database layer are located in two different machines. It means that the client and the server are not on the same computer.
The client, which is the user side device gives the instructions. Then the server which stores all the data and information is asked to provide the required data or make changes in the existing data. The business layer is present on the server machine. Both the user interface or the presentation layer and database layer communicate with each other through the Internet, Transfer Control Protocol, Internet Protocol.
It is easy to maintain and modify the 2 tier application architecture. Even the communication between client and server in the form of request and response is very quick. But the disadvantage with this architecture is that, if the number of clients crosses the capacity then the server finds it unable to respond to the requests made by clients. It decreases the productivity of the server The application is also required to be reinstalled in the client if some changes are done in the application. Since the business layer resides on the client-side so the client has to be of high processing power.
3 – Tier Architecture
In 3 tier architecture, the layer, the business layer and the database layer are located in separate machines. Unlike 2 tier architecture, 2 servers perform the major tasks in this application. One server is for the business layer and the other is the database layer.
This architecture is used to design a web application. The client layer request for the data. The application server act as an interface between the client and the server layer. The application layer helps the client in communicating with the server. It receives the request from the client and sends it to the database, which then responds and the required information reaches the client passing the application layer.
The database layer store all of the data and respond according to the application layer logic. This layer also increases the security of the application. The main goal of 3 tier architecture is to separate the client application and the physical database, program data independence and support multiple views.
Advantages of the Client-Server Network
Following are the benefits of a client-server network:
Less damage since one client computer does not impact other computers in the network.
Easy recovery of files is possible since backups are centrally controlled by network administrators.
More secure since files and everything else is centralized on such networks.
Larger networks can be created as new clients and servers can be added to the network. This makes this network more scalable.
Easy sharing of resources is possible due to the control from the server.
Expandable storage capacity allows more data to be available on the server. Even hard drives can be added the server in an easy manner.
The server is highly accessible since it can be accessed remotely from multiple platforms.
Disadvantages of the Client-Server Network
While there are a number of benefits of such network, there are a following limitations as well:
An expert professional is always required for maintaining the server which makes it complex.
Due to the lack of resources, there is a possibility of system overload which in turn leads to network traffic congestion.
It is more expensive since servers are costly to buy, set up and maintain.
Any damage to the server will hamper the entire network #
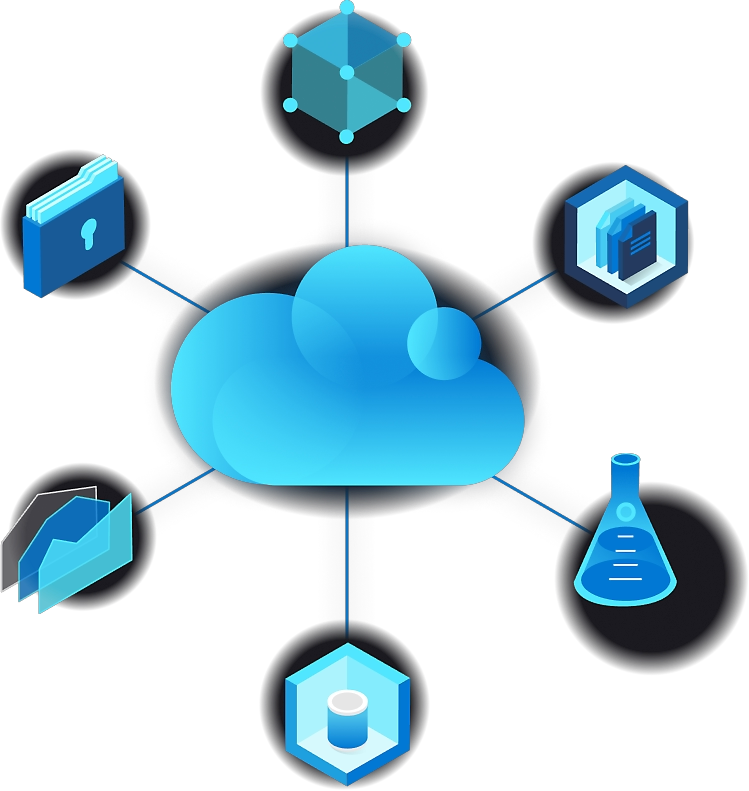
Cloud Computing
Simply put, cloud computing is the delivery of computing services—including servers, storage, databases, networking, software, analytics, and intelligence—over the internet (“the cloud”) to offer faster innovation, flexible resources, and economies of scale. You typically pay only for cloud services you use, helping you lower your operating costs, run your infrastructure more efficiently, and scale as your business needs change.
Cloud computing Service Model
IaaS
The most basic category of cloud computing services. With infrastructure as a service (IaaS), you rent IT infrastructure—servers and virtual machines (VMs), storage, networks, operating systems—from a cloud provider on a pay-as-you-go basis.
PaaS
Platform as a service (PaaS) refers to cloud computing services that supply an on-demand environment for developing, testing, delivering, and managing software applications. PaaS is designed to make it easier for developers to quickly create web or mobile apps, without worrying about setting up or managing the underlying infrastructure of servers, storage, network, and databases needed for development.
SaaS
Software as a service (SaaS) is a method for delivering software applications over the internet, on demand and typically on a subscription basis. With SaaS, cloud providers host and manage the software application and underlying infrastructure, and handle any maintenance, like software upgrades and security patching. Users connect to the application over the internet, usually with a web browser on their phone, tablet, or PC.
In Linux, a running programme is called a process. It is a programme instance that the Linux kernel is now running. Every process has an own set of resources, including memory and CPU time, as well as a unique process ID (PID).
A process is given a unique identity known as its Process ID (PID).
Process States
One of the following states is possible for a process within the system:
sprinting It is running the code at the moment.
All set: It is prepared to operate, but CPU time is needed.
Sleeping: It is momentarily stopped and is awaiting the occurrence of a procedure or event.
Stopped: Either the user or the system stops it.
Zombie: Although the process has finished running, it still has a record in the process table.
Process Management
To control the processes, use the following command.
ps
ps aux
ps aux | grep username [replace username with your username in the system]
cat /proc/<PID>/status [replace <PID> with actual process ID]
top: a real-time process monitor that shows details about every process that is active. Try it out
top
top -u root
top -u username [replace username with your username in the system]
gnome-system-monitor [opens GUI based system monitor]
kill: a technique for ending a process. Test out kill
kill <PID> [replace <PID> with actual process ID]
kill -9 <PID> [-9 for forcefully, SIGKILL signal]
You may also use the systemctl command if your system has any installed services. Try it out
sudo systemctl status service_name [replace the service_name with actual service name]
sudo systemctl start service_name
sudo systemctl stop service_name
Network Configuration
You can access all the network interfaces name with command
-ifconfig or ip addr or ip link
You can access the routing information of network that your device is connected to with the command
-ip route
You can get the configuration file inside the /etc/netplan/ folder. It will have a default configuration file in YAML format. By default it uses the NetworkManger to manage your network.
You can get the configuration about the specific network you are connected to from /etc/NetworkManager/system-connections/<connection-name>
You can go inside the /etc/NetworkManager/system-connections/ folder and list all the network connections names.
Other network configuration files are
-/etc/host.conf - contains order in which hostname are resolved
-/etc/hosts - map ip address to hostname/domain name
-/etc/hostname - contains name of your system hostname which can be used to identify your system in the network.
-Some of the other files are /etc/hosts.deny and /etc/hosts.allow
Network Commands
netstat - used to display various network information [routing table, interfaces,connection, ports, etc..]
ping - test host connection reachability
traceroute - find out the path between source and destination
nslookup - obtain mapping between ip address and domain name and vice versa
ssh - remote login using the shell
Firewall Configuration
We will utilise the built-in ufw (uncomplicated firewall) firewall. It is easy to operate. Try using the commands sudo ufw status and sudo ufw enable (if the status is not active, use this one).
You may now use the command to ban a specific website.
sudo ufw forbid out to <ip-address> [substitute the website's real IP address for the address; use the nslookup command to find out the address].
To reload a firewall, use sudo ufw reload.
If you want to unblock it, you can use the following command
sudo ufw delete deny out to <ip-address>
If you want to disable the firewall, you can use the following command
A Linux operating system's built-in layer called the Linux file system is typically used to manage storage device data.
The structure of the Linux file system is tree-like. The directory tree is another name for the structure that resembles a tree.It controls a file's name, size, creation date, and a tonne of other details.
Representing and organising the system's storage resources is the fundamental function of a filesystem.
Other files and folders can be found in its root directory.
Pathnames
A pathname is a text string consisting of one or more names, such as assignment 02 /check, /var/log/auth.log,./etc/passwd, etc., separated by forward slashes (/).
A pathname is a series of names that tells the hierarchical file system tree where to find a certain item.
Pathnames that begin with a slash specify locations that are relative to the root of the pathname space (/).
For example:
- /home
- /etc/password
- usr /wc
- /vaar/ntpstats loopstats
The filesystem is shown as a single, cohesive structure that descends via an infinite number of subdirectories from the directory.
Another name for the root directory is /.
Under a single tree hierarchical file system structure, Unix/Linux files are arranged into directories that may contain additional subdirectories and files, as well as files that contain data (such as documents and programmes).
File Type in Linux
Everything in a Linux system is a file, and everything that isn't a file is a process.
Seven different file types are defined by most file system implementations.
Developers must still make the file tree appear like one of these seven categories even when they add something amazing and unique, like the process information beneath /.
Regular files
Directories
Character device files
Block device files
Local domain sockets
Named pipes (FIFO)
Link files
Regular or Ordinary files
Text, music, video, photos, scripts, and programmes are just a few of the content kinds that may be stored in regular or ordinary files.
The vast majority of files on Linux and UNIX are standard files.
Regular files in Linux can be generated either way around an extension.
Standard files begin with -
Directories
Named references to other files can be found within a directory.
It is a binary file that is used to find and track other directories and files.
Directories can be created using mkdir and, if they are empty, deleted using rmdir.
Directories are used by file systems to arrange files in a hierarchy.
A directory called /, or the root directory, is where the Linux file system begins.
This directory is where all files and directory files are produced. Every directory, aside from the root directory, has a parent directory.
Special Files: Character device and Block device file
Hard drives, printers, displays, terminal emulators, and CD/DVD drives are just a few examples of the hardware devices that Linux handles as unique files.
To expose the device as a file in the file system is the goal of a special file.
Because tools for file I/O may access the device, a particular file offers a universal interface for physical devices (including virtual devices produced and utilised by the kernel).
Data written to or read from a special file occurs instantly and is not governed by standard filesystem conventions.
A character special file is an example of a device, like a printer or monitor, that sends data in bytes. A block special file is an example of a device, like a hard disc, that transmits data in blocks.
a block-specific special file that grants access to a device that sends data in fixed-size groups. As an instance, a disc.
a unique character file that grants access to a device—like a terminal—that sends data in single-character increments.
Link files: Hard link And Soft links
We can utilise a file from a different place and with a different filename thanks to link files. Link files are used for this.
A pointer to another file is found in a link file. connections come in two varieties: symbolic or soft connections and hard linkages.
The original file is mirrored when a hard link is used.
You cannot make a hard link to a file or directory on a different filesystem.#
By name, a symbolic or "soft" link refers to a specific file.
It is possible to make a soft link to a file or directory on a different filesystem.
Socket Files:
Applications utilise sockets as communication endpoints to share data.
For instance, a programme on the local system connects to the socket of a distant application using the port number and IP address of the remote application in order to interact with it.
Sockets are used by all programmes that accept connections from distant clients or other applications.
Every socket has a port number and IP address that enable it to receive connections from clients.
Linux employs socket files to facilitate communication between local programmes.
Applications running on the local system can communicate data using socket files without requiring the complicated networking and sockets procedure.
The unique files known as socket files are those that refer to themselves by their file name rather than by their IP address and port number.
The sendmsg() and recvmsg() system functions are used by socket files to provide inter-process communication between nearby programmes.
Named Pipes:
Named pipes facilitate communication between two processes that are operating on the same host, much as local domain sockets.
Another name for them is "FIFO files."
Mknod can be used to build named pipes, while rm may be used to delete them.
The functions of named pipes and local domain sockets are identical, and their existence is largely an artefact of the past.
If UNIX and Linux were created today, network sockets would probably be used in place of both of them.
Copies files and directories, including their content
mv
Moves or renames files and directories
touch
Creates a new empty file
file
Checks a file’s type
zip and unzip
Creates and extracts a ZIP archive
tar
Archives files without compression in a TAR format
nano, vi, and jed
Edits a file with a text editor
cat
Lists, combines, and writes a file’s content as a standard output
grep
Searches a string within a file
sed
Finds, replaces, or deletes patterns in a file
head
Displays a file’s first ten lines
tail
Prints a file’s last ten lines
awk
Finds and manipulates patterns in a file
sort
Reorders a file’s content
cut
Sections and prints lines from a file
diff
Compares two files’ content and their differences
tee
Prints command outputs in Terminal and a file
locate
Finds files in a system’s database
find
Outputs a file or folder’s location
sudo
Runs a command as a superuser
su
Runs programs in the current shell as another user
chmod
Modifies a file’s read, write, and execute permissions
chown
Changes a file, directory, or symbolic link’s ownership
useradd and userdel
Creates and removes a user account
df
Displays the system’s overall disk space usage
du
Checks a file or directory’s storage consumption
top
Displays running processes and the system’s resource usage
htop
Works like top but with an interactive user interface
ps
Creates a snapshot of all running processes
uname
Prints information about your machine’s kernel, name, and hardware
hostname
Shows your system’s hostname
time
Calculates commands’ execution time
systemctl
Manages system services
watch
Runs another command continuously
jobs
Displays a shell’s running processes with their statuses
kill
Terminates a running process
shutdown
Turns off or restarts the system
ping
Checks the system’s network connectivity
wget
Downloads files from a URL
curl
Transmits data between servers using URLs
scp
Securely copies files or directories to another system
rsync
Synchronizes content between directories or machines
lfconfig
Displays the system’s network interfaces and their configurations
netstat
Shows the system’s network information, like routing and sockets
traceroute
Tracks a packet’s hops to its destination
nslookup
Queries a domain’s IP address and vice versa
dig
Displays DNS information, including record types
history
Lists previously run commands
man
Shows a command’s manual
echo
Prints a message as a standard output
ln
Links files or directories
alias and unalias
Sets and removes an alias for a file or command
cal
Displays a calendar in Terminal
apt-get
Manages Debian-based distros package libraries
Linux Commands for File and Directory Management
This section will explore basic Linux commands for file and directory management.
1. ls command
The ls command lists files and directories in your system. Here’s the syntax:
ls [/directory/folder/path]
If you remove the path, the ls command will show the current working directory’s content. You can modify the command using these options:
-R – lists all the files in the subdirectories.
-a – shows all files, including hidden ones.
-lh – converts sizes to readable formats, such as MB, GB, and TB.
2. pwd command
The pwd command prints your current working directory’s path, like /home/directory/path. Here’s the command syntax:
pwd [option]
It supports two options. The -L or –-logical option prints environment variable content, including symbolic links. Meanwhile, -P or –physical outputs the current directory’s actual path.
3. cd command
Use the cd command to navigate the Linux files and directories. To use it, run this syntax with sudo privileges:
cd /directory/folder/path
Depending on your current location, it requires either the full path or the directory name. For example, omit /username from /username/directory/folder if you are already within it.
Omitting the arguments will take you to the home folder. Here are some navigation shortcuts:
cd ~[username] – goes to another user’s home directory.
cd .. – moves one directory up.
cd- – switches to the previous directory.
4. mkdir command
Use the mkdir command to create one or multiple directories and set their permissions. Ensure you are authorized to make a new folder in the parent directory. Here’s the basic syntax:
mkdir [option] [directory_name]
To create a folder within a directory, use the path as the command parameter. For example, mkdir music/songs will create a songs folder inside music. Here are several common mkdir command options:
-p – creates a directory between two existing folders. For example, mkdir -p Music/2023/Songs creates a new 2023 directory.
-m – sets the folder permissions. For instance, enter mkdir -m777 directory to create a directory with read, write, and execute permissions for all users.
-v – prints a message for each created directory.
5. rmdir command
Use the rmdir command to delete an empty directory in Linux. The user must have sudo privileges in the parent directory. Here’s the syntax:
rmdir [option] directory_name
If the folder contains a subdirectory, the command will return an error. To force delete a non-empty directory, use the -p option.
6. rm command
Use the rm command to permanently delete files within a directory. Here’s the general syntax:
rm [filename1] [filename2] [filename3]
Adjust the number of files in the command according to your needs. If you encounter an error, ensure you have the write permission in the directory.
To modify the command, add the following options:
-i – prompts a confirmation before deletion.
-f – allows file removal without a confirmation.
-r – deletes files and directories recursively.
Warning! Use the rm command with caution since deletion is irreversible. Avoid using the -r and -f options since they may wipe all your files. Always add the -i option to avoid accidental deletion.
7. cp command
Use the cp command to copy files or directories, including their content, from your current location to another. It has various use cases, such as:
Copying one file from the current directory to another folder. Specify the file name and target path:
cp filename.txt /home/username/Documents
Duplicating multiple files to a directory. Enter the file names and the destination path:
The touch command lets you create an empty file in a specific directory path. Here’s the syntax:
touch [option] /home/directory/path/file.txt
If you omit the path, the command will create the item in the current folder. You can also use touch to generate and modify a timestamp in the Linux command line.
The file command lets you check a file type – whether it is a text, image, or binary. Here’s the syntax:
file filename.txt
To bulk-check multiple files, list them individually or use their path if they are in the same directory. Add the -k option to display more detailed information and -i to show the file’s MIME type.
11. zip, unzip commands
The zip command lets you compress items into a ZIP filewith the optimal compression ratio. Here’s the syntax:
zip [options] zipfile file1 file2….
For example, this command compresses note.txt into archive.zip in the current working directory:
The tar command archives multiple items into a TAR file– a format similar to ZIP with optional compression. Here’s the syntax:
tar [options] [archive_file] [target file or directory]
For instance, enter the following to create a new newarchive.tar archive in the /home/user/Documents directory:
tar -cvzf newarchive.tar /home/user/Documents
Linux Commands for Text Processing and Searching
The following section explores several Linux commands for processing and searching text.
13. nano, vi, jed commands
Linux lets users edit files using a text editor like nano, vi, or jed. While most distributions include nano and vi, users must install jed manually. All these tools have the same command syntax:
nano filename
vi filename
jed filename
If the target file doesn’t exist, these editors will create one. We recommend nano if you want to quickly edit text files. Meanwhile, use vi or jed for scripting and programming.
The global regular expression or grep command lets you find a word by searching the content of a file. This Linux command prints all lines containing the matching strings, which is useful for filtering large log files.
For example, to display lines containing blue in the notepad.txt file, enter:
The sed command lets you find, replace, and delete patterns in a file without using a text editor. Here’s the general syntax:
sed [option] 'script' input_file
The script contains the searched regular expression pattern, the replacement string, and subcommands. Use the s subcommand to replace matching patterns or d to delete them.
At the end, specify the file containing the pattern to modify. Here’s an example of a command that replaces red in colors.txt and hue.txt with blue:
sed 's/red/blue' colors.txt hue.txt
17. head command
The head command prints the first ten lines of a text file or piped data in your command-line interface. Here’s the general syntax:
head [option] [file]
For instance, to view the first ten lines of note.txt in the current directory, enter:
head note.txt
The head command accepts several options, such as:
-n – changes the number of lines printed. For example, head -n 5 showsthe first five lines.
-c – prints the file’s first customized number of bytes.
The tail command displays the last ten lines of a file, which is useful for checking new data and errors. Here’s the syntax:
tail [option] [file]
For example, enter the following to show the last ten lines of the colors.txt file:
tail -n colors.txt
19. awk command
The awk command scans regular expression patterns in a file to retrieve or manipulate matching data. Here’s the basic syntax:
awk '/regex pattern/{action}' input_file.txt
The action can be mathematical operations, conditional statements like if, output expressions such as print, and a delete command. It also contains the $n notation, which refers to a field in the current line.
To add multiple actions, list them based on the execution order, separated using semicolons. For example, this command contains mathematical, conditional, and output statements:
awk -F':' '{ total += $2; students[$1] = $2 } END { average = total / length(students); print "Average:", average; print "Above average:"; for (student in students) if (students[student] > average) print student }' score.txt
20. sort command
The sort command rearranges lines in a file in a specific order. It doesn’t modify the actual file and only prints the result as Terminal outputs. Here’s the syntax:
sort [option] [file]
By default, this command will sort the lines in alphabetical order, from A to Z. To modify the sorting, use these options:
-o – redirects the command outputs to another file.
-r – reverses the sorting order to descending.
-n – sorts the file numerically.
-k – reorders data in a specific field.
21. cut command
The cut command retrieves sections from a file and prints the result as Terminal outputs. Here’s the syntax:
cut [option] [file]
Instead of a file, you can use data from standard input. To determine how the command sections the line, use the following options:
-f – selects a specific field.
-b – cuts the line by a specified byte size.
-c – sections the line using a specified character.
-d – separates lines based on delimiters.
You can combine these options, use a range, and specify multiple values. For example, this command extracts the third to fifth field from a comma-separated list:
cut -d',' -f3-5 list.txt
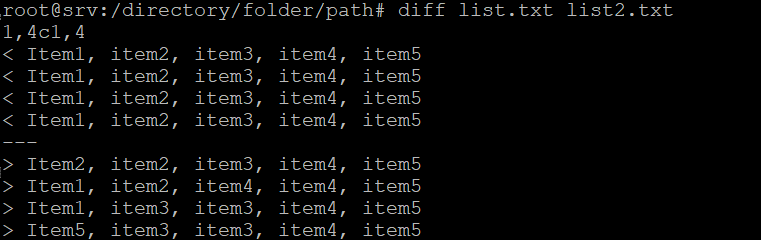
22. diff command
The diff command compares two files’ content and outputs the differences. It is used to alter a program without modifying the code. Here’s the general format:
diff [option] file1 file2
Below are some acceptable options:
-c – displays the difference between two files in a context form.
-u – shows the output without redundant information.
The locate command lets you find a file in the database system. Add the -i option to turn off case sensitivity and an asterisk (*) to find content with multiple keywords. For example:
locate -i school*note
The command searches for files containing school and note, regardless of their letter case.
25. find command
Use the find command to search for files within a specific directory. Here’s the syntax:
find [option] [path] [expression]
For example, to find a file called file1.txt within the directory folder and its subdirectories, use this command:
find /home -name file1.txt
If you omit the path, the command will search the current working directory. You can also find directories using the following:
find ./ -type d -name directoryname
Linux Commands for User and Permission Management
Below are several Linux commands for managing the system’s users and permissions.
26. sudo command
Superuser do or sudo is one of the most basic commands in Linux. It runs your command with administrative or root permissions. Here’s the general syntax:
sudo (command)
When you run a sudo command, Terminal will request the root password. For example, this snippet runs useradd with the superuser privilege:
sudo useradd username
You can also add an option, such as:
-k – invalidates the timestamp file.
-g – executes commands as a specified group name or ID.
-h – runs commands on the host.
Warning! Running a command with sudo privileges can modify all aspects of your system. Since misusing it may break your system, run the command with caution and only if you understand its possible repercussions.
27. su command
The su command lets you run a program in the Linux shell as a different user. It is useful to connect via SSH while the root user is disabled. Here’s the syntax:
su [options] [username [argument]]
Without any option or argument, thiscommand runs through root and prompts you to use the sudo privileges temporarily. Some options are:
-p –keeps the same shell environment, consisting of HOME, SHELL, USER, and LOGNAME.
-s – lets you specify another shell environment to run.
-l –runs a login script to switch users. It requires you to enter the user’s password.
To check the current shell’s user account, run the whoami command:
In Linux, each file is associated with three user classes – owner, group member, and others. It also has three permissions – read, write, and execute. If an owner wants to grant all permissions to every user, the command looks like this:
If you don’t specify the item, this command will display information about every mounted file system. These are some acceptable options:
-m – displays information on the file system usage in MBs.
-k – prints file system usage in KBs.
-T – shows the file system type in a new column.
32. du command
Use du to check a file or directory’s storage consumption. Remember to specify the directory path when using this command, for example:
du /home/user/Documents
The du command has several options, such as:
-s –shows the specified folder’s total size.
-m –provides folder and file information in MB.
-k – displays information in KB.
-h –informs the displayed folders and files’ last modification date.
33. top command
The top command displays running processes and the system’s real-time condition, including resource utilization. It helps identify resource-intensive processes, enabling you to disable them easily.
The htop command is an interactive program for monitoring system resources and server processes. Unlike top, itoffers additional features like mouse operation and visual indicators. Here’s the command syntax:
htop [options]
It supports options such as:
-d – shows the delay between updates in tenths of seconds.
-C – enables monochrome mode.
-h – displays the help message and exits.
35. ps command
The ps command creates a snapshot of all running processes in your system. Executing it without an option or argument will list the running processes in the shell with the following information:
Unique process ID (PID).
Type of the terminal (TTY).
Running time (TIME).
Command that launches the process (CMD).
The ps command accepts several options, including:
-T – displays all processes associated with the current shell session.
-u username – lists processes associated with a specific user.
Use time to measure commands’ execution time. Here’s the syntax:
time [commandname]
To measure a series of commands, separate them using semicolons or double ampersands (&&). For example, we will measure cd, touch, and chmod commands’ overall execution time:
time cd /home/directory/path; touch bashscript.sh; chmod +x bashscript.sh
39. systemctl command
The systemctl command lets you manage installed services in your Linux system. Here’s the basic syntax:
systemctl [commandname] [service_name]
To use the command, the user must have root privilege. It has several use cases, including starting, restarting, and terminating a service. You can also check a service’s status and dependencies.
The systemctl command is only available in Linux distributions with the Systemd init system. Check our article on listing and managing Linux services to learn more about other systems’ commands.
The watch command lets the user continuously run another utility at a specific interval and print the results as a standard output. Here’s the syntax:
watch [option] command
It is useful for monitoring command output changes. To modify itsbehavior, use the following options:
-d – displays the differences between command executions.
-n – changes the default two-second interval.
-t – disables the header containing the time interval, command, timestamp, and hostname.
41. jobs command
The jobs command displays a shell’s running processes with their statuses. It is only available in csh, bash, tcsh, and ksh shells. Here’s the basic syntax:
jobs [options] jobID
To check the status of jobs in the current shell, enter jobs without any argumentsin Terminal. The command will return an empty output if your system doesn’t have running jobs. You can also add the following options:
-l – lists process IDs and their information.
-n – shows jobs whose statuses have changed since the last notification.
Use the kill command to terminate an unresponsive program using its identification number (PID). To check the PID, run the following command:
ps ux
To stop the program, enter the syntax below:
kill [signal_option] pid
There are 64 signals for terminating a program, but SIGTERM and SIGKILL are the most common. SIGTERM is the default signal that lets the program save its progress before stopping. Meanwhile, SIGKILL forces programs to stop and discard unsaved progress.
The Linux shutdown command lets you turn off or restart your system at a specific time. Here’s the syntax:
shutdown [option] [time] "message"
You can use an absolute time in a 24-hour format or a relative one like +5 to schedule it in five minutes. The message is a notification sent to logged-in users about the system shutdown.
Instead of shutting down, restart the system using the -r option. To cancel a scheduled reboot, run the command with the -c option.
Linux Commands for Network Management and Troubleshooting
Here are commonly used Linux commands for managing and troubleshooting network connections.
The ping command is one of the most used commands in Linux. It lets you check whether a network or server is reachable, which is useful for troubleshooting connectivity issues. Here’s the syntax:
ping [option] [hostname_or_IP_address]
For example, run the following to check the connection and response time to Google:
The curl command transfers data between servers. Its common usage is for retrieving a web page’s content to your system using its URL. Here’s the syntax:
curl [option] URL
However, you can add various options to modify the curl command behavior for other tasks. Some of the most popular ones include:
The rsync command lets you sync files or folders between two destinations to ensure they have the same content. Here’s the syntax:
rsync [options] source destination
If your destination or source is a folder, enter the directory path like /home/directory/path. To sync a remote server, use its hostname and IP address, like host@185.185.185.185.
This command has various options:
-a – enables archive mode to preserve file permissions, dates, and other attributes.
-v – shows visual information about the transferred file.
-z – compresses the transferred file data to reduce their size.
49. ifconfig command
The ifconfig command lets you list and configure your system’s network interface. In newer Linux distros, it is equivalent to the ip command. Here’s the basic syntax:
ifconfig [interface] [option]
Running it without arguments displays information about all network interfaces in your system. To check a specific interface, add its name as an argument without an option. For a more specific task, use the following options:
–s – summarizes the network interfaces and their configuration. This option goes before the interface name.
up and down – enables and disables a network interface.
inet and inet6 – assigns an IPv4 and IPv6 address to a network interface.
netmask – specifies the subnet mask to use with an IPv4 address.
50. netstat command
The netstat command is used to display your system’s network information, like sockets and routing. Here’s the command syntax:
netstat [option]
Use various options to modify the displayed information. Some common ones are:
-a – displays listening and closed sockets.
-t – shows TCP connections.
-u – lists UDP connections.
-r – displays routing tables.
-i – shows information about network interfaces.
-p – lists programs’ names and process IDs.
-c – continuously outputs network information for real-time monitoring.
51. traceroute command
The traceroute command tracks a packet’s path when it moves to another host over a network. It gives you information about the involved routers and travel time. Here’s the syntax:
traceroute [option] destination
You can use a domain, hostname, or IP address as the destination. Add the following options for more detailed packet monitoring:
-m – sets each packet’s maximum hops.
-n – prevents the command from resolving IP addresses to hostnames for quicker tracing.
-I – changes the default UDP packets to UCMP.
-w – adds a timeout in seconds.
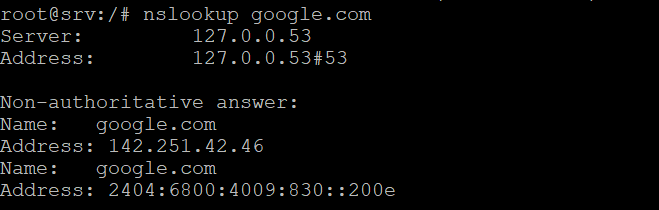
52. nslookup command
The nslookup command queries a DNS server to find out the domain associated with an IP address and vice versa. Here’s the syntax:
nslookup [options] domain-or-ip [server]
If you don’t specify the DNS server to use, nslookup will use the default resolver from your system or internet service provider. This command supports various options, with some commonly used ones being:
-type= – queries specific information, like the IP address type or MX record.
-port= – sets the DNS server’s port number for the query.
-retry= – repeats the query a specific number of times upon failure.
-debug – enables the debug mode to provide more information about the query.
The dig or domain information groper command gathers DNS data from a domain. Unlike nslookup, it is more detailed and versatile. Here’s the syntax:
dig [option] target [query_type]
Replace target with a domain name. By default, this command only shows A record type. Change query_type to check a specific type or use ANY to query all of them. To run a reverse DNS lookup, add the -x option and use the IP address as the target.
Miscellaneous Linux Commands
In this section, we will list Linux commands with various functions.
54. history command
Enter history to list previously executed commands. It lets you reuse the commands without rewriting them. To use it, enter this syntax with sudo privileges:
history [option]
To rerun a specific utility, enter an exclamation mark (!) followed by the command’s list number. For example, use the following to rerun the 255th command:
!255
This command supports many options, such as:
-c – clears the history list.
-doffset –deletes the history entry at the OFFSET position.
-a – appends history lines.
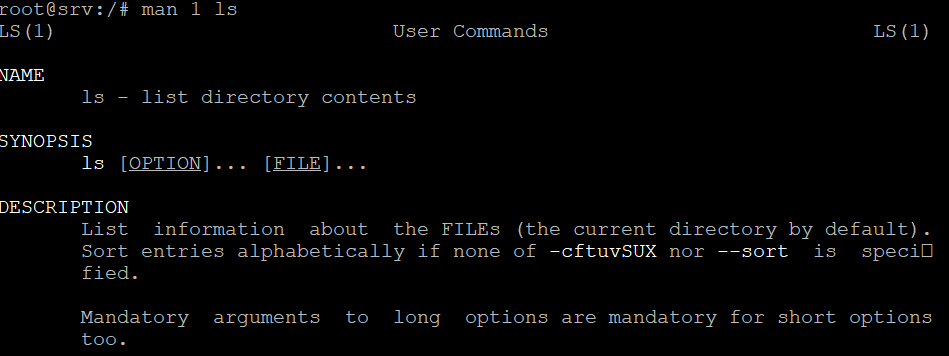
55. man command
The man command provides a user manual of any Linux Terminal utilities, including their names, descriptions, and options. It consists of nine sections:
Executable programs or shell commands
System calls
Library calls
Games
Special files
File formats and conventions
System administration commands
Kernel routines
Miscellaneous
Here’s the command syntax:
man [option] [section_number] command_name
If you only use the command name as the parameter, Terminal displays the full user manual. Here’s an example command to query section 1 of the ls command manual:
man 1 ls
56. echo command
The echo command displays a line of text as a standard output. Here’s the basic command syntax:
echo [option] [string]
For example, you can display Hostinger Tutorials by entering:
echo "Hostinger Tutorials"
This command supports many options, such as:
-n – displays the output without the trailing newline.
-e –enables the interpretation of the following backslash escapes:
The ln command lets you create links between files or directories to simplify system management. Here’s the syntax:
ln [option] [source] [destination]
The command will create the target file or directory and link it to the source. By default, it creates a hard link, meaning the new item connects to the same data block as the source.
58. alias, unalias commands
The alias command instructs the shell to replace a string with another, allowing you to create a shortcut for a program, file name, or text. Here’s the syntax:
alias name=string
For example, enter the following to make k the alias for the kill command:
alias k='kill'
This command doesn’t give any output. To check the alias associated with a command, run the following:
alias command_name
To delete an existing alias, use the unalias command with the following syntax:
unalias [alias_name]
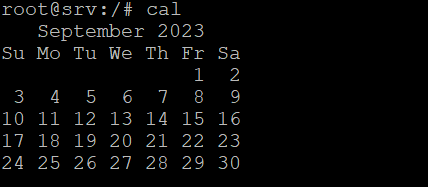
59. cal command
The cal command outputs a calendar in the Linux Terminal. It will show the current date if you don’t specify the month and year. Here’s the syntax:
cal [option] [month] [year]
The month is in the numerical representation from 1–12. To modify the command output, add the following options:
-1 – outputs the calendar in a single line.
-3 – shows the previous, current, and next month.
-A and -B – displays the specified number of months after and before the current one.
-m – starts the calendar with Monday instead of Sunday.
60. apt-get command
apt-get is a command line tool for handling Advanced Package Tool (APT) libraries in Debian-based Linux, like Ubuntu. It requires sudo or root privileges.
This Linux command lets you manage, update, remove, and install software, including its dependencies. Here’s the main syntax:
apt-get [options] (command)
These are the most common commands to use with apt-get:
update –synchronizes the package files from their sources.
upgrade –installs the latest version of all installed packages.
check – updates the package cache and checks broken dependencies.
Linux Commands Tips and Tricks
Here are some tips for using Linux commands and Terminal to improve your system management efficiency:
Add the –help option to list the full usage of a command.
Use the exit command to close Terminal.
Enter the clear command to clean the Terminal screen.
Press the Tab button to autofill after entering a command with an argument.
Use Ctrl + C to terminate a running command.
Press Ctrl + Z to pause a working command.
Use Ctrl + A to move to the beginning of the line.
Press Ctrl + E to bring you to the end of the line.
Separate multiple commands using semicolons (;) or double ampersands (&&).